As we mentioned in the first section of this module, a key element of open software includes using tools that enable human and machine interpretable content so that even if a particular piece of software is no longer available, a human should still be able to understand what the intent of the code was.
When we talk about open in the context of creating human and machine interpretable code, we’re talking about organized, documented code supported through scripting and literate programming.
Programs can be shared either as source code (as the programmer wrote it) or compiled (a format intended only for machine-reading, not to be read directly by people). Sharing a compiled program allows someone else to use it, but does not allow them to see the internals of how the program operates, or modify it to behave differently.
Readable Code
It’s all well and good if we make our code available by the ethos of Free and Open Source Software (FOSS) and engage in literate programming when compiling our data and outputs. But if the syntax and structure of our code are not clear, we are no more transparent than the black box of 0s and 1s we are trying to overcome.
Writing clear code that a human can make sense of is critical for both transparency and reproducibility in the research life cycle.
So, what does readable code look like? The following video Readable Code (3:59) from Khan Academy gives a pretty good overview of how code can be made more accessible to a human reader. Don’t focus on the actual coding language but on the principles of making it readable.
There are a lot of opinions out there on just what makes readable code readable code. After all, some of our most beloved authors break all the rules of good grammar. Some manage to explain the world in a single sentence, while others will fill pages with the briefest moment. In general, this concept is captured well in the WTF per Minute measurement:
“Cars have MPH (Miles per Hour) that measures the speed that they travel. The better the car the faster the MPH or speed. Developers have WTFPM (WTF per Minute) that measures the number of ‘Works That Frustrate’ that the developer can read per minute, aka code quality…With a car, the BETTER the road the more MPH it can attain. With a developer, the WORSE the code the more WTFPM can be obtained.”
The short of it though is that all rules will be contextual, depending on why you’re writing what you’re writing and who your audience is. As well as the reality that conventions exist in certain circles of programmers, researchers, and learners.

Dig Deeper
Written for programmers, the introductory content in this book is widely applicable: The Art of Readable Code: Simple and Practical Techniques for Writing Better Code, by Dustin Boswell and Trevor Foucher.
Note The above text is available only to UBC Library card holders. I know. The irony in a module about Open. We’re actively seeking an alternative that is open. In the mean time, you can check availability at your local library using WorldCat and putting in your postal code.
Using GenAI Tools to Create Readable Code
Large language models can be incredibly helpful in both creating readable code and understanding code written by others.
You can paste in a snippet of code and ask the model to explain what it does, break it down line by line, and summarize its purpose in plain language. This is especially useful when working with obscure libraries or unfamiliar programming styles. Similar to pair-programming, using an LLM can save a lot of time when you get stuck or are having a hard time understanding how a piece of code works.
Using an LLM as a coding assistant for code generation can also help you to iterate quickly. You can ask it to write single functions or whole data processing scripts based on natural language descriptions of what you want to achieve. It can also generate boilerplate code, set up test cases, or help scaffold a new project. This makes prototyping much faster and lowers the barrier to entry for people who are newer to programming or working in unfamiliar languages. That said, generated code definitely needs review and testing, as the model might make assumptions or use outdated practices.
When trying to write clear and readable code, it’s good practice to follow norms and conventions. Programming languages and major libraries or frameworks all have their own conventions, and individual large software projects may have their own internal styles as well. When using GenAI tools to help write code, you’ll need to be aware of the conventions and likely modify the generated output to match the style of your project.
One of the greatest benefits of open software is reuse. One author can create and maintain a library of code to solve a particular software challenge, and many other people can re-use that library. Over time improvements can be made to the library, and all of its users can benefit from the changes. Particularly in areas such as cybersecurity and cryptography, it’s very important to use well established, thoroughly vetted software libraries, rather than creating your own or letting an LLM create one for you. LLMs are great at generating new code, but sometimes you will need to steer them towards reusing an existing library instead.
Dig Deeper
To learn more:
- Explore a short course on Pair Programming with an LLM
- “Vibe Coding” is a term used to describe writing code entirely by prompting an LLM to generate code. You can watch a demonstration here
Literate Programming
Clean, readable code is just the first step in increasing our transparency and reproducibility. Literate programming takes us to the next level.
Formally introduced by Donald Knuth, literate programming is inspired by a shift in how one’s code is communicated; the goal being to, as Knuth states:
“[i]nstead of imagining that our main task is to instruct a computer what to do, let us concentrate rather on explaining to human beings what we want a computer to do… [achieved] … by considering programs to be works of literature.”
Knuth, Donald E. (1984). “Literate Programming”. The Computer Journal. 27: 97–111.
Common implementations of literate programming that you may have heard about include R Markdown and Jupyter Notebooks.
What is R?
R has taken academia by storm. R is a programming language that is becoming commonplace in many disciplines. R is open source and community developed. It is great for statistical analyses. It makes beautiful visualizations from your data. Thanks to community efforts it has add-ons that produce gorgeous documents, allowing you to write something once and export it to html, pdf, or Microsoft Word.
Is R the be-all and end-all?
No. Open, reproducible work flows should be tool agnostic. R just happens to very accessible and well supported. And it is what we’ll be referring to when we talk about scripted programming in this module. You’ll find plenty of alternatives, and more about R, on the Additional Open Software page!
Example of Literate Programming
The following is an example of what literate programming looks like.
First, we have a traditional output, a pdf, that we might be used to seeing; this includes some text and a few tables or graphs. We have no insights into how the data has been handled, and how the visualizations were derived (select the image to view the pdf). Sharing this pdf works well to communicate our findings, but does not enable others to see or reuse the details of our data manipulation.
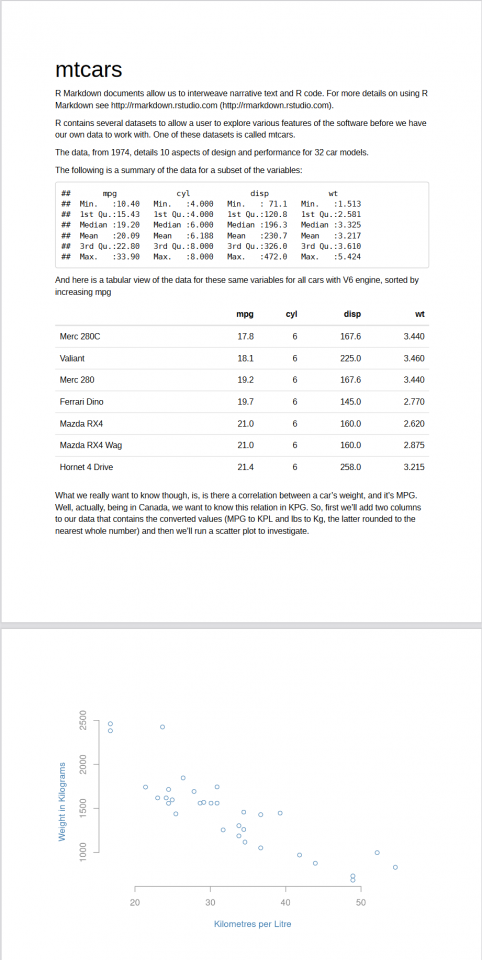
Secondly, we have the underlying document that generated the above, written using R Markdown. It integrates the code used to generate the above document! If on a system using R, and the tools to interpret R Markdown, it can be used to generate the above document, making our work reproducible. Better still, this document is written in plain text, so it can be opened by virtually any text based program, making our work transparent; even without access to R, we can still read the below and understand how the processing was handled. It’s also highly reusable: someone could easily perform an identical analysis on a different dataset, or change the plotting parameters to produce a different visualization.
---
title: "mtcars"
output: pdf_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = FALSE)
```
R Markdown documents allow us to interweave narrative text and R code. For more details on using R Markdown see <http://rmarkdown.rstudio.com>.
R contains several datasets to allow a user to explore various features of the software before we have our own data to work with. One of these datasets is called mtcars.
The data, from 1974, details 10 aspects of design and performance for 32 car models.
The following is a summary of the data for a subset of the variables:
```{r}
summary(mtcars[c(1:3,6)])
```
And here is a tabular view of the data for these same variables for all cars with V6 engine, sorted by increasing mpg
```{r}
library(kableExtra) # load needed libraries
# select and view subset of data in tabular format
V6 <- mtcars[order(mtcars$mpg, decreasing = FALSE),] %>%
subset(cyl == 6)
V6[c(1:3, 6)] %>%
kbl() %>%
kable_styling()
```
What we really want to know though, is, is there a correlation between a car's weight, and it's MPG. Well, actually, being in Canada, we want to know this relation in KPG. So, first we'll add two columns to our data that contains the converted values (MPG to KPL and lbs to Kg, the latter rounded to the nearest whole number) and then we'll run a scatter plot to investigate.
```{r}
mwt <- round(mtcars$wt * 1000 * 0.45359237, digits = 0) # convert imperial to metric and round off
kpl <- mtcars$mpg * 1.609 # convert imperial to metric
mmtcars <- cbind(mtcars, mwt, kpl) # add metric data to existing data set
# plot
plot(mmtcars$kpl, mmtcars$mwt, xlab = "Kilometres per Litre", ylab = "Weight in Kilograms", col = "#4682b4", fg = "#888888", col.lab = "#4682b4", col.axis = "#888888", bty = "n")
```
Test your knowledge
Dig Deeper
To learn more about literate programming and readable code, look into the following:
- An interesting web site with a host of resources and references about literate programming: http://www.literateprogramming.com/
- 20250422: this site is down, but the Internet Archive has a recent copy
- An excerpt from an interview with Donald Knuth on Literate Programming
- A good overview written for tidyverse, but widely applicable: The tidyverse style guide, by Hadley Wickham
