Next, we’ll guide you through the steps to make your research data open: planning, describing, and preserving and sharing.
Plan
Before collecting your data you need to create a project sharing plan. It is relatively easy to put a dataset on a website or upload it into a project in OSF, but messy or poorly managed data does not help with its reuse. Each stage of the data life cycle should be considered when planning how you will manage your data and make it accessible. A Data Management Plan (DMP) helps you articulate how you will manage your data at each stage from collection to analysis to preservation. DMP tools such as the DMP Assistant or the DMP Tool, can guide you through each step and help save you endless headaches in the long run. You can also use a checklist to help guide your decision making process.
Like open access and open data requirements, some research funders may request a DMP to be submitted with a funding application.
Describe
Metadata
As introduced in the Open Workflows module, metadata are a requirement of open data and describe the content and structure of a project/files. There are three types of metadata:
- Descriptive: Help people find or understand the context. Project title, authors, keywords and collection methods are all types of descriptive metadata.
- Administrative: Provides technical, preservation and rights information. This metadate may include: information about what software is required to use the data, file size, copyright status and license terms.
- Structural: Provides information about how the data files relate to one another. You can add additional metadata file links and publication links.
Test your knowledge
Readme Files
A plain text readme file is often included alongside data files to assist others in understanding your data. it should include all necessary metadata or indicate which files contain other metadata. A readme ensures that the data can be interpreted by researchers as it includes the contents and structure of the dataset. Readme files may also contain variable level metadata (for example, what does the .csv column labeled var 1 contain), but reporting variable level metadata is often discipline specific and may sometimes instead be recorded in a separate data dictionary, codebook or other documentation format. This Disciplinary Metadata repository can teach you more about your own disciplinary standards.
Readme Example
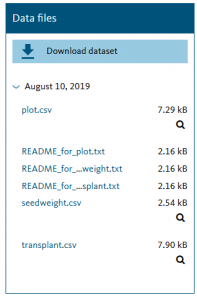
Review this example readme file: https://doi.org/10.5061/dryad.j0t179b. Following the image the left, open the drop down to reveal the files associated with the data. Review the readme files to see how the authors have provided guidance to interpret their data set. Note that the file structure allows you to associate the appropriate .csv file with its related readme and the readme files help interpret the related .csv file.

Dig Deeper
- Tidy-ing Your Data: Simple Steps for Reproducible Research (video)
- Data Management Skill Building Hub: Learn more about the planning and describing stages from DataONE
- Learn the difference between readme, data dictionary, and codebooks
- Creating a README for your dataset: A template created by UBC Library
